The 2025 International Conference on Learning Representations (ICLR) is happening this week in Singapore. We’re excited to share the work that will be presented and published by the group and our collaborating authors. You can find links to our ICLR 2025 papers below!
BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models
Language models often struggle with reliable and consistent decisions under uncertainty, partially because they can’t reliably estimate the probability of each choice. We propose BIRD, a framework that significantly enhances LLM decision making under uncertainty. BIRD leverages LLMs for world modeling and constructs a Bayesian network using LLM-generated variables, enabling interpretable and trustworthy probability estimates.
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). For reliable assessment, each standard instance in MuirBench is paired with an unanswerable variant that has minimal semantic differences.
Fei Wang, Xingyu Fu, James Y. Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao Chen, MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding ICLR (2025)
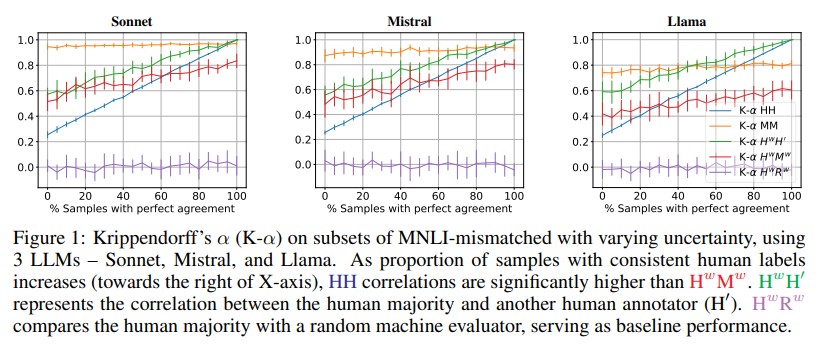
Beyond correlation: The Impact of Human Uncertainty in Measuring the Effectiveness of Automatic Evaluation and LLM-as-a-Judge
The effectiveness of automatic evaluation of generative models is typically measured by comparing labels generated via automation with labels by humans using correlation metrics. In this paper, we show how *relying on a single aggregate correlation score* can obscure fundamental differences between human labels and those from automatic evaluation, including LLM-as-a-Judge. Based on these findings, we propose stratifying data by human label uncertainty to provide a more robust analysis and introduce a new metric to better measure the effectiveness of automatic evaluations.
Updated with presentation times and dates (note: not chronological, even though the first one is on April 30; so is the last). ___ * Here’s a blog post from the NAACL organizing committee about their name change.
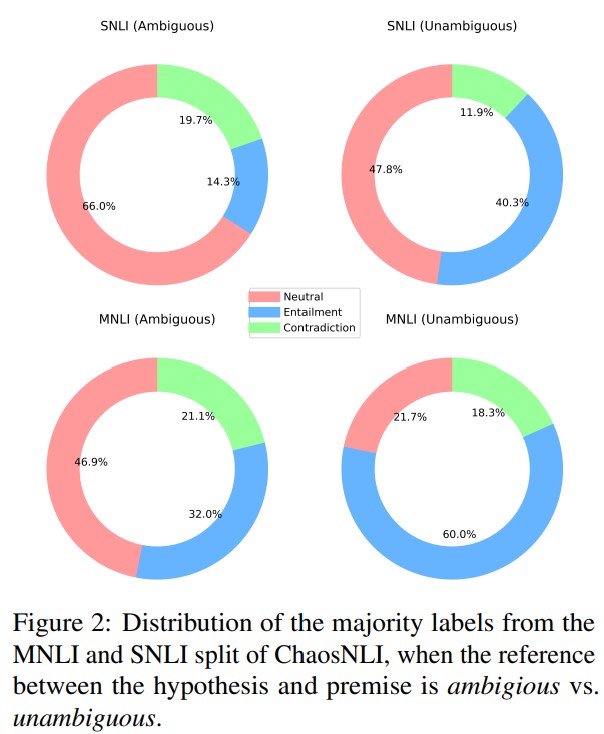
On Reference (In-)Determinacy in Natural Language Inference
This paper introduces RefNLI, a diagnostic benchmark for identifying reference ambiguity in Natural Language Inference examples. We provide insight into how the reference determinacy assumption (the assumption that premise and hypothesis refer to the same context) impacts the downstream utility of NLI models, and discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI.
Wednesday, April 30, Session C: Oral/Poster 2, Hall 3, 14:00-15:30.
Towards Long Context Hallucination Detection
This paper studies hallucination detection where the context length is long (>=512 tokens). We construct a dataset to evaluate the task and propose a method to approach it.
Siyi Liu, Kishaloy Halder, Zheng Qi, Wei Xiao, Nikolaos Pappas, Phu Mon Htut, Neha Anna John, Yassine Benajiba, and Dan Roth, Towards Long Context Hallucination Detection. NAACL Findings (2025)
Friday, May 2, Session J: Oral/Poster 7, Hall 3, 9:00-10:30.
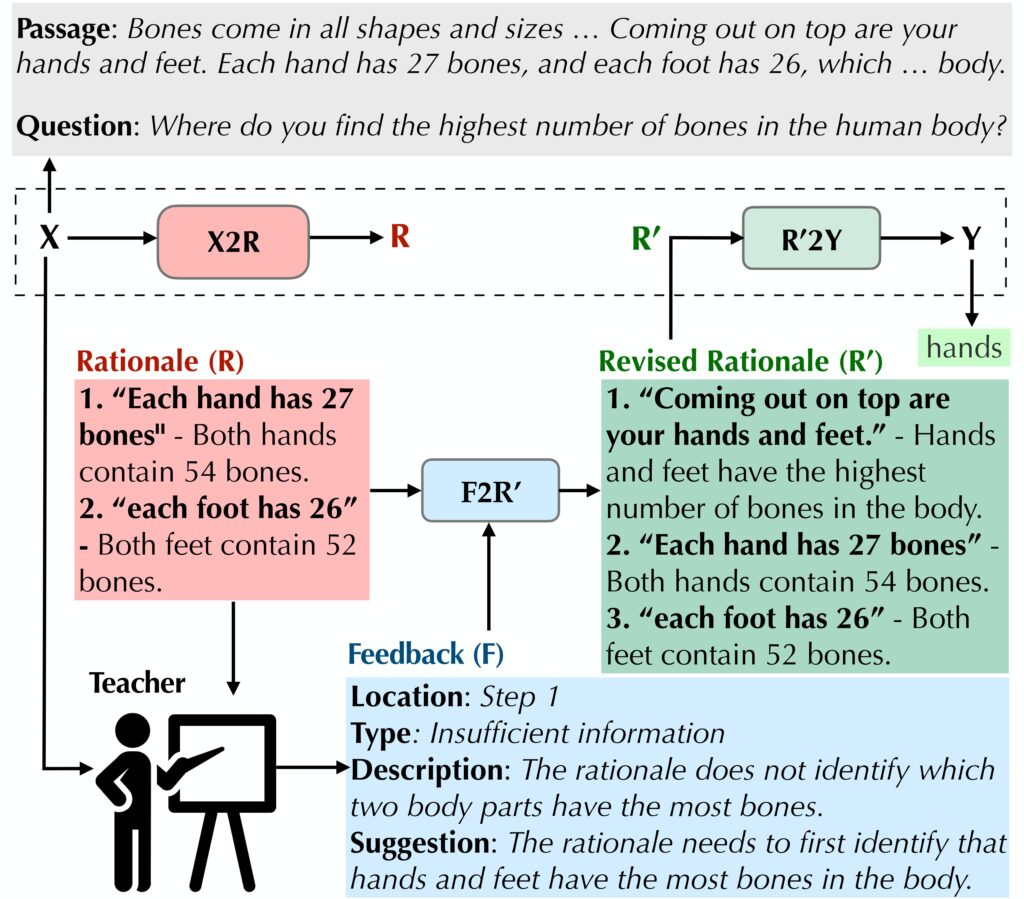
Open Domain Question Answering with Conflicting Contexts
We study open domain question answering when there is conflicting evidence presented on the web. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guides them through the process of reasoning with conflicting contexts.
Friday, May 2, Session J: Oral/Poster 7, Hall 3, 9:00-10:30.
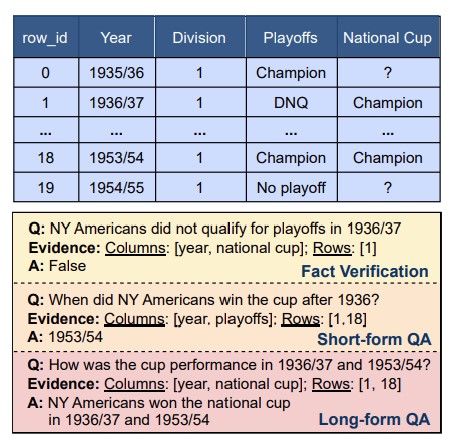
H-STAR: LLM-driven Hybrid SQL-Text Adaptive Reasoning on Tables
Existing approaches to tabular reasoning employ either textual reasoning, which excels in semantic interpretation but struggles with mathematical operations, or symbolic reasoning, which handles computations well but lacks semantic understanding. H-STAR, a novel method introduced in this paper, integrates text comprehension with SQL-like logic to effectively answer queries from structured tables.
Thursday, May 1, Session H: Oral/Poster 5, Hall 3, 14:00-15:30.
TRANSIENTTABLES: Evaluating LLMs’ Reasoning on Temporally Evolving Semi-structured Tables
The ability to reason over time allows us to identify future steps and to understand the effects of decisions on our lives. However, large language models are typically trained on static datasets, limiting their ability to perform effective temporal reasoning. To assess the temporal reasoning capabilities of LLMs, this paper presents the TRANSIENTTABLES dataset, with questions derived from over 14,000 tables, spanning multiple time periods.
Friday, May 2, Session K: Oral/Poster 8, 11:00-12:30 (presentation 11:45).
Enhancing Temporal Understanding in LLMs for Semi-structured Tables
We introduce the C.L.E.A.R. prompting framework and auxiliary cross-format training to enhance LLM performance in temporal tabular reasoning. Our findings demonstrate that our method improves evidence-based reasoning across various models. Additionally, our experimental results reveal that indirect supervision with auxiliary unstructured data (TRAM) substantially boosts model performance.
Thursday, May 1, Session H: Oral/Poster 5, Hall 3, 14:00-15:30.
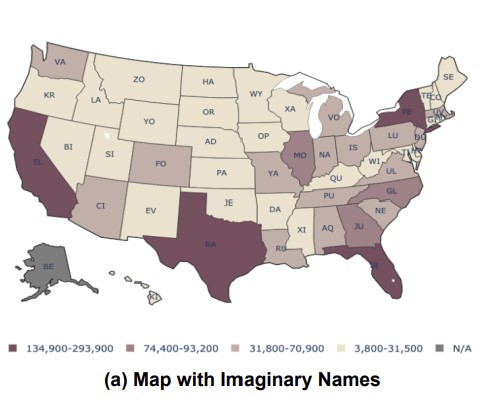
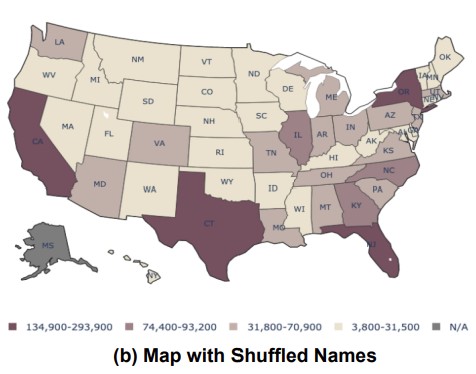
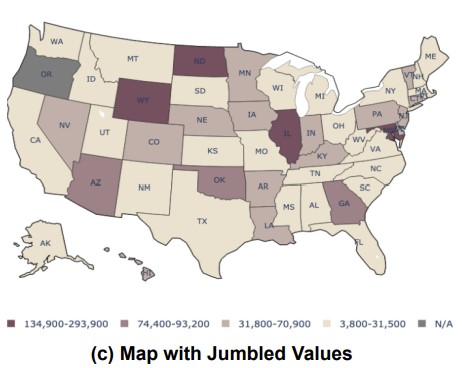
MAPWise: Vision-Language Models for Advanced Map Queries
Revised maps with counterfactual data, forcing the models to rely on the maps themselves.
This paper introduces a new benchmark for evaluating vision-language models (VLMs) on choropleth map question answering, featuring diverse maps and question types across multiple geographic regions. Evaluation of several VLMs reveals significant performance gaps, highlighting the need for further research in this area and providing a resource for future model development.
NTSEBENCH: Cognitive Reasoning Benchmark for Vision Language Models
NTSEBENCH is a Vision-Language Model benchmark dataset with 2,728 questions and 4,642 images from India’s NTSE exam, to evaluate VLMs on cognitive multimodal reasoning.
Friday, May 2, Session K: Oral/Poster 8, Hall 3, 11:00-12:30.
Aligning to Constraints for Data-Efficient Language Model Customization
This paper proposes ACT (Aligning to ConsTraints), a unified and efficient Language Model customization framework using automatic constraint verifiers to provide supervision signals for adapting models to downstream tasks.
Tuesday, May 6, Gather Session 2, online, 15:00-16:30.
Leveraging LLM For Synchronizing Information Across Multilingual Tables
We explored the application of large language models (LLMs) for multilingual information synchronization, focusing on improving the accuracy and coherence of updates to Wikipedia tables in low-resource languages.
Muhao Chen joined the Cognitive Computation Group in 2019 as a postdoctoral researcher, and he still collaborates with us from time to time.
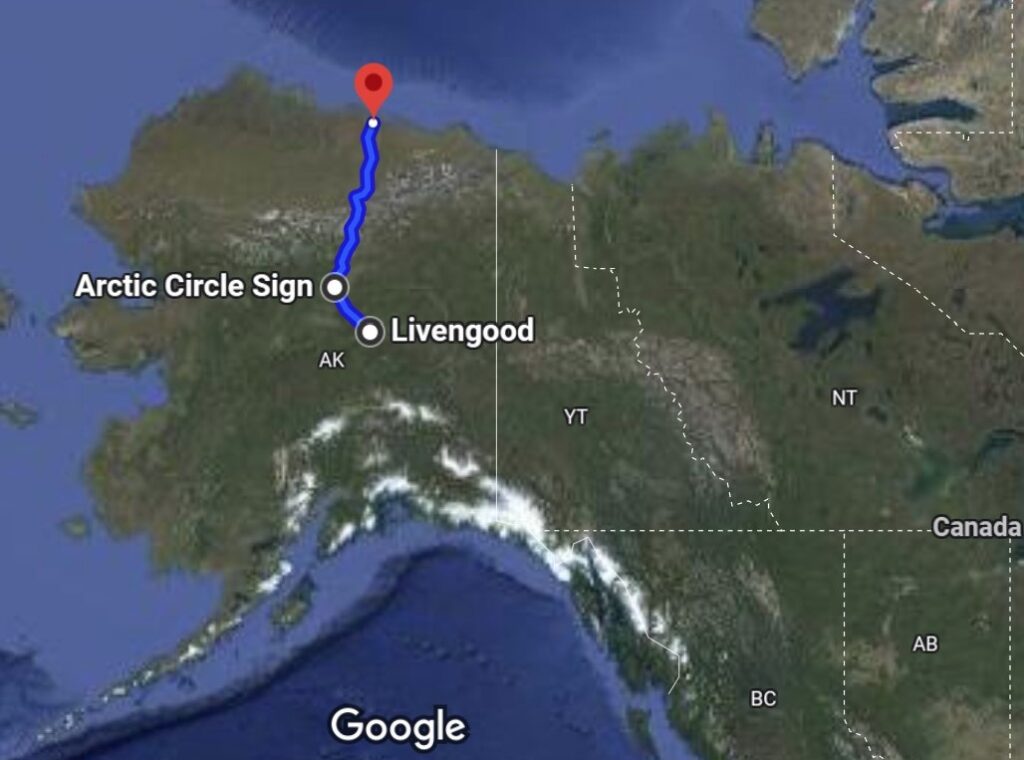
Muhao Chen at the Arctic Circle, holding up the earth.
He is currently an Assistant Professor in the Department of Computer Science at UC Davis. He directs the Language Understanding and Knowledge Acquisition (LUKA) Lab. Muhao’s research focuses on robust and minimally supervised data-driven machine learning for Natural Language Processing. Most recently, his group’s research has been focusing on accountability and security problems of large language models and multi-modal language models. Previously, Muhao was a Postdoctoral Fellow at UPenn, from 2019 to 2020. He received his Ph.D. degree from the Department of Computer Science at UCLA in 2019. Before joining UCLA as a Ph.D. student, he graduated with a Bachelor degree from Fudan University in 2014.
Hi, Muhao! Glad to catch up with you. Please tell me where you’re living and what you’re up to these days.
I’m living in Sacramento — the capital city of California. As usual, aside from working, I still enjoy traveling (especially driving to different places for road trips). Luckily, from Sac or the Bay Area it is easy to reach most places in the country through direct flights or driving.
That’s excellent! I’m glad you’ve been getting to travel. What are the most rewarding things about your current work?
What I feel most rewarding is to have had a well-established NLP group since I started to work as a faculty member. All students have done excellent jobs building strong academic records of their own. Over a year ago, the first batch of PhD students graduated and have been very successful researchers in the industry. A few more are upcoming and are looking for (or will soon be looking for) faculty positions (wish them the best of luck!). Hope one day, the group can be as successful as CCG and have a lot of successful alumni.
The most surprising? And yes, best of luck to them!
Most of my group members have pets (mostly cats; as we list in one of the sections here https://luka-group.github.io/people.html). I recently got my own pets (two Roborovski hamsters):
They’re very sweet. I like that the nonhumans get special recognition in your lab. (-:
How connected is your work now with what you did in our group?
NLP has been moving way too fast nowadays. But quite a few things we’ve done recently, especially those related to LLM reasoning and indirect supervision, are closely related to what I did at CCG. In fact, I still collaborate with Dan and other (past or current) CCG members like Ben, Wenpeng, Haoyu, Hongming, and Qiang on these topics. We have been giving tutorials every year since 2020 about this research.
What new development(s) in the field of NLP are you excited about right now?
Our group has been focusing on machine learning robustness since it was founded. Particularly, we recently have been very interested in safety issues of LLMs. We build systems that automatically identify safety issues of LLMs, safeguard LLMs from malicious use, and protect LLMs from threats and vulnerabilities when they interact with complex environments. This area is particularly important nowadays considering that LLMs are becoming backbones of more and more intelligent systems and are starting to handle thousands of tasks in real world.
I’m glad to hear you’re focusing on safety issues as LLMs grow. Thoughts about the state of AI?
This is an exciting time where AI researchers are building larger and larger learning-based systems and not only solve daily-life problems, but even help with frontier scientific discovery in many other fields like biology, medicine, chemistry, food science, etc. On the one hand, it is a good time for us to work with other fields of study on many scenarios where AI can contribute its force. On the other hand, it is an important time where academia should collaborate more closely with the industry as the AI systems we seek to build recently require significantly more computing and data resources.
How are things outside of work?
I just finished my checklist for traveling to all the national parks in US. Last summer I drove the Dalton Highway to reach the Gates of the Arctic.
Congratulations! That’s fantastic. So, how many national parks have you visited? And which have made a particular impression on you?
I’ve been to 56 national parks (only counting real “National Parks”, and not national monuments or national historical parks etc. though I’ve been to many of these as well). There are 7 national parks I still haven’t been to (3 in Alaska, 1 island in California, 1 island in Florida, and 1 in American Samoa and 1 in Virgin Islands) because all these need to be reached by air taxis or cruise ships, while I just finished all that can be reached by driving. I really love the national park system in the US because almost every one of them is different from each other, with many unique scenes to see and roads to drive on.
Favorite park: if one, then definitely Yellowstone that stands out from all the rest. But I’ve been asked to pick my top 5 in the past and I eventually picked the top 6: Yellowstone (WY), Death Valley (CA), Arches (UT), Carlsbad Cavern (NM), Redwood (CA), Badlands (SD).
Excellent! Do you have a memory to share from your time with the group?
It was campus lock-down time in 2020, but a few of us had hotpot every Friday at my apartment. In fact, a few of us still spent time together in the 3401 Walnut building during the lock-down. A lot of fun happened during that time. There were times where we stayed late in the building before the paper deadline. There were also times where we brought game consoles to play in the room where Dan used to host his group meeting. Most of them have graduated now (except for Haoyu).
Any advice for the current students and postdocs in the group?
One important thing I learned from Dan is to develop a good research taste. Doing meaningful research is not about publishing more and more papers. In fact, only the first paper, the best paper, and probably also the last paper about a topic are the memorable ones.
Thanks for this insight. And thank you so much for this interview!
For more information on Muhao Chen’s research at UC Davis, please visit his website.
Just looked this up: the 414 mile Dalton Highway in Alaska, including the 100+ mile stretch Muhao would have driven to reach the Arctic Circle!
This summer, for the first time in a few years, we had a substantial group of summer interns working with us, mentored by PhD student Sihao Chen and postdoc Vivek Gupta. Some were visiting from universities as far away as Utah and California, but the group also included a Penn undergrad and a local high schooler. We were honored to work with them and incorporate them into our research work. As the summer term winds up, I’ve asked for their thoughts on the experience and what they learned and enjoyed here!
Harshavardhan Kalalbandi Master’s student at the University of California, Riverside
My internship at Prof. Dan Roth’s Cognitive Computation Group has been an incredible journey. During the first few weeks I spent time going through many research papers to formulate a good problem. I found a keen interest in temporal QA on tables, where the tables can be represented in various ways. We started by establishing baselines using existing reasoning methods. We proposed a dynamic reasoning approach, allowing the model to have flexibility in formulating its approach. Initially, we tried solving the problem through simple prompting, but when that proved insufficient, we explored alternative approaches.
Harsha on a trip to Washington, DC
Our efforts led us to develop a multi-agent approach and a fine-tuning method for our system. A significant challenge has been keeping pace with the rapid advancements in state-of-the-art NLP research. A highlight of this experience was meeting Prof. Dan Roth and his incredible team, which was both inspiring and fun. Dr. Vivek Gupta’s mentorship and expertise was very helpful in seeing through this work. I also explored the incredible campus of Penn, went around Philadelphia, and traveled to New York City and DC during the weekends. It was a great fun experience where I learned a lot, met incredible people, and enjoyed myself.
Kushagra Dixit Master’s student at the University of Utah
This summer, I had the amazing opportunity to intern with the Cognitive Computation Group at the University of Pennsylvania. During my time here, I worked on two fascinating domains: improving the temporal understanding of large language models on semi-structured data and exploring the mechanisms behind in-context learning in LLMs. These projects allowed me to delve deep into some of the most exciting trends in NLP research, providing invaluable experience that I will carry forward in my career.
Kushagra on a trip to Washington, DC
One of the most enjoyable aspects of this internship has been the vibrant and collaborative environment. I’ve had the pleasure of interacting with PhD students in the lab, sharing ideas with fellow interns, and receiving invaluable guidance from Dr. Vivek Gupta. Every discussion with Professor Dan Roth has been particularly special. His insights and expertise have consistently challenged and inspired me, leaving a profound impact on my approach to research. I will leave this internship not only with a wealth of new knowledge but also with cherished memories of the fun and engaging moments shared with the team.
In terms of skills, I’ve significantly sharpened my programming abilities, but more importantly, I’ve learned how to drive a research project from inception to completion. Engaging with so many experienced researchers has provided me with numerous opportunities to understand their thought processes, which has been a critical learning experience. As I move forward, I am excited to continue my engagement with CogComp, building on the strong foundation this internship has provided, and contributing further to NLP research.
Mike Zhou Undergrad at the University of Pennsylvania
Mike at Mission Peak, San Francisco
Hi! My name is Mike and I’m currently a rising senior at Penn. This summer, I’ve had the pleasure to be a part of the cognitive computation lab, where I’ve been focusing on language model reasoning and understanding. My current projects involve exploring large language models’ abilities to reason, and whether their reasoning comes from a form of deduction or simply from semantic associations. My day-to-day routine in the lab involves keeping up with literature, designing experiments that I’ll run, and talking with other lab mates to give and gain insights on each other’s projects. Overall, I’d say that I’ve learned quite a bit about and gained a good number of insights on language models this summer, whether it was from my work, peers, or Professor Roth.
Yanzhen Shen Undergrad at the University of Illinois Urbana-Champaign
Hi! I’m Yanzhen Shen, an undergraduate student at the University of Illinois at Urbana-Champaign. This summer, I had the privilege of conducting research at the University of Pennsylvania under Professor Dan Roth and my PhD mentor, Sihao Chen. During this experience, I worked on cutting-edge research in Information Retrieval and gained a deeper understanding of the qualities of a good researcher.
Yanzhen in Chicago
Our project focused on improving retrieval systems, particularly for complex queries. While current systems handle simple queries effectively, they struggle with ones with logical operators, such as “Orchids of Indonesia and Malaysia but not Thailand.” To address this, we are using text embedding models to better interpret logical operators like AND, OR, and NOT in complex queries. Our goal was to push the boundaries of how query and document dense embeddings can represent complex information.
Technically, I became proficient in dual encoder training frameworks and data processing for Information Retrieval tasks.
More importantly, discussions with Professor Roth helped me view our ideas from broader perspectives. For example, he continued to encourage me to think about how our model differs from existing dense retrieval models and other retrieval systems. In addition, working closely with Sihao also gave me insights into how a senior PhD student approaches and resolves challenges in complex research problems. We also engaged in paper discussions, where he taught me to think about critical questions when reading papers, such as “What makes a good researcher question?” and “ Is this work influential?”
Atharv Kulkarni Undergrad at the University of Utah
Atharv in conversation with Benjamin Franklin
This summer, I had the incredible opportunity to intern at the University of Pennsylvania’s Cognitive Computation group under the guidance of Professor Dan Roth. The main focus of my internship was to enhance the capabilities of language models for complex reasoning tasks using neurosymbolic approaches. I created a question-answer dataset based on the Wikipedia information of Olympic sport athletes and used it to evaluate state-of-the-art language models. This involved integrating Wikipedia data into a database and developing SQL queries to create a large synthetic dataset. I discovered that models often struggle with temporal reasoning tasks, which led to productive discussions with Professor Roth about using neurosymbolic techniques to improve reasoning performance. By refining models with fine-tuning and prompt engineering, I made significant progress in enhancing language models’ ability to transform natural language questions into SQL queries.
Beyond the technical work, Professor Roth’s mentorship was invaluable. His insightful feedback and guidance helped me develop skills in fine-tuning models and utilizing various APIs, significantly advancing my understanding of the field. His expertise provided me with a deeper appreciation for the nuances of research and inspired me to think critically about complex problems. Mentoring Aadit Bontha, a high school student interning with our CogComp group, was a rewarding experience, offering me a fresh perspective on language models. Exploring Philadelphia’s iconic sites, such as City Hall and the Benjamin Franklin Museum, along with my peers, added to the memorable experiences of this summer. Overall, I gained a deeper understanding of research and thoroughly enjoyed collaborating with my peers. I am grateful to Professor Dan Roth and Dr. Vivek Gupta for this invaluable opportunity.
Aadit Bontha HS Student at La Salle College High School
During my internship at UPenn, I had the opportunity to work on a project centered around large language models (LLMs) and their ability to extract and organize data from various sources. My main task was to explore how these models could generate structured answers, like tables, from diverse data inputs—a challenge that required both technical skill and a deep understanding of AI.
Mentor Vivek Gupta with Aadit, holding matching program certificates
I started by working with the TANQ dataset, which includes a vast collection of question-answer pairs. My role involved extracting relevant information and using LLMs to generate structured outputs. This required extensive coding in Python, utilizing tools like BeautifulSoup for web scraping and the JSON module for data parsing.
One of the most interesting aspects of the internship was experimenting with different AI models, such as GPT-3.5 and Gemini 1.5. Through this, I gained insights into how these models perform in various scenarios—GPT-3.5 excels at handling complex queries, while Gemini 1.5 is more effective with simpler, structured tasks.
I also focused on refining the prompts we used to optimize model performance. This involved understanding how to craft questions that would elicit the most accurate and relevant responses from the models. Overall, the internship was a highly educational experience that enhanced my skills in AI and data processing, providing me with valuable insights into the practical applications of these technologies.
The 2024 Annual Meeting of the Association for Computational Linguistics (ACL) is underway in Bangkok! We’re excited to share the work that’s being presented and published from CCG and our collaborating authors. You can find links to our ACL papers below!
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models
In this position paper, we argue that human evaluation of generative large language models (LLMs) should be a multidisciplinary undertaking that draws upon insights from disciplines such as user experience research and human behavioral psychology to ensure that the experimental design and results are reliable. To design an effective human evaluation system in the age of generative NLP, we propose the ConSiDERS-The-Human evaluation framework, consisting of 6 pillars — Consistency, Scoring Criteria, Differentiating, User Experience, Responsible, and Scalability.
Winner of the Outstanding Paper Award at the ACL2024 Workshop on Knowledgeable LMs Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Retrieving relevant tables containing the necessary information to accurately answer a given question over tables is critical to open-domain question-answering (QA) systems. However, many questions require retrieving multiple tables and joining them through a join plan that cannot be discerned from the user query itself. In this paper, we introduce a method that uncovers useful join relations for any query and database during table retrieval. We use a novel re-ranking method formulated as a mixed-integer program that considers not only table-query relevance but also table-table relevance that requires inferring join relationships.
FlowVQA: Mapping Multimodal Logic in Visual Question Answering with Flowcharts
This paper introduces FlowVQA to overcome the shortcomings of existing visual question answering benchmarks in visual grounding and spatial reasoning. FlowVQA features 2,272 flowchart images and 22,413 question-answer pairs to evaluate tasks like information localization, decision-making, and logical reasoning. The evaluation of various multimodal models highlights FlowVQA’s potential to advance multimodal modelling and improve visual and logical reasoning skills.
Evaluating LLMs’ Mathematical Reasoning in Financial Document Question Answering
In this paper, we assess LLM robustness in complex mathematical reasoning with financial tabular datasets, revealing that LLMs struggle with increasing table and question complexity, especially with multiple arithmetic steps and hierarchical tables. The new EEDP technique enhances LLM accuracy and robustness by improving domain knowledge, extracting relevant information, decomposing complex questions, and performing separate calculations.
Celine Lee joined the Cognitive Computation Group as an undergraduate/masters student researcher in 2019 and graduated from Penn in 2020. She is now a PhD candidate at Cornell Tech. Celine explores questions in structured language, particularly problems in programming language semantics and reasoning.
Hi, Celine! Please tell me where you’re living and what you’re doing these days.
I live in New York City, working on my PhD at Cornell Tech, the campus on Roosevelt Island.
What are the most rewarding things about your current work?
The most fun thing about research is how big the search space of problems is. I get to spend every day thinking about where the interesting open problems are, then talking and working with some of the brightest minds in the field to devise experiments to address them. Most days don’t look the same, because I can’t predict what the path to the solution exactly looks like.
The most surprising?
Something that still surprises me every day is how small this community really is. I’ll meet a friend of a friend or join some colleagues for lunch, and suddenly I’m putting all these new faces to the names on papers that I have been reading for years. And everyone is so excited to talk about what we’re all obsessed with: our shared research interests!
That’s great! I remember your passion for research from your work with us at Penn. How did you originally get involved with the group? I remember you participated in the Google Explore Research program in early 2020.
This is correct! I started working with Dan after taking his machine learning course, then got involved with the Google Explore Program soon after.
How connected is your work now with what you did in our group?
At CCG, I was working on semantic role labeling systems. Now I’m continuing my work on structured language tasks, but the grammar is that of computer programming languages. The tension of the differing levels of ambiguity between natural language and high level programming languages down the compute stack to compiler IRs all the way to bits leads to interesting questions about correctness, scalability, and adaptability of automatic programming systems.
What are your thoughts about the state of AI?
Many brilliant people are asking and answering many questions that make computers more adept than I ever imagined possible. I was skeptical at first, then a bit scared, then ultimately excited because now I have more powerful tooling to think bigger– tackle some crazier ideas.
That does sound exciting! I know you also parlay your varied interests into creative work alongside your academic work. Will you talk a bit about your writing?
Over the pandemic, I found myself with an unprecedented abundance of time to explore topics only barely related to my work. This coincided with my increasing involvement with NLP research, through which I (1) learned a structured methodology for asking and answering questions, and (2) became extra interested in language. So I wrote and put out my first few blog posts, which turned out to be surprisingly super fun.
snippet from “Donut Wheel”
Fast forward through the the past few years, and this hobby has spiraled out into various formats– academically-leaning blog posts, short and silly illustrated zines, personal musings and essays… Side benefit of writing as a personal creative endeavor: writing papers for work is much less intimidating now.
We have a number of undergrad and master’s students joining us as interns this summer. Any advice or thoughts about working with the group?
I have two primary pieces of advice. One is that Professor Roth’s expertise and experience make not only him one of the best people you could work with and learn from, but also all the other people around you in the lab. It would be wise to talk to everyone and learn their specialties so that you can maximize your surrounding resources.
The other piece of advice is to practice storytelling as much as possible– who are you as a researcher? Why is your work a compelling piece of science in todays massive volume of NLP work? I think you should be able to convince someone who isn’t personally invested in you but is interested in machine learning to root for your success.
That’s excellent advice. Thank you so much for this interview! To learn more about Celine’s research and creative pursuits, please visit her website.
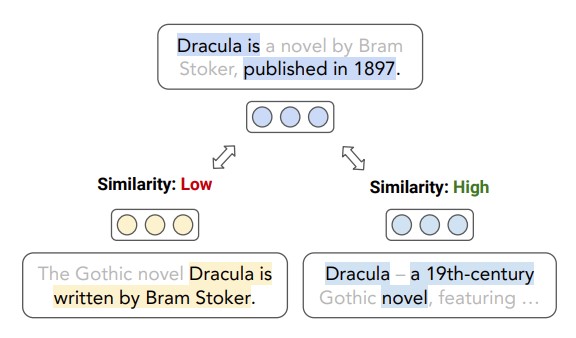
Sub-Sentence Encoder: Contrastive Learning of Propositional Semantic Representations
Figure 1: Given a proposition in a sentence (represented by a highlighted subset of tokens), the sub-sentence encoder produces a contextual embedding for the meaning of the proposition.
Text embeddings typically produce one embedding for the entire text sequence, but what if the text is long and says many things? Check out Sub-Sentence Encoder — A contextual text encoder model that learns to embed individual pieces of meaning in text.
What if you said that differently?: How Explanation Formats Affect Human Feedback Efficacy and User Perception
In this work, we study the effect of intermediate explanation formats on the effectiveness of human feedback for correcting QA model responses. Further, we investigate the properties of explanations which allow users to understand and trust responses.
ExpertQA: Expert-Curated Questions and Attributed Answers
This work conducts expert evaluation of responses to domain-specific questions according to various axes of attribution and factuality. Based on our evaluation, we present ExpertQA, a high-quality long-form QA dataset with 2177 questions spanning 32 fields, along with verified answers and attributions for claims in the answers.
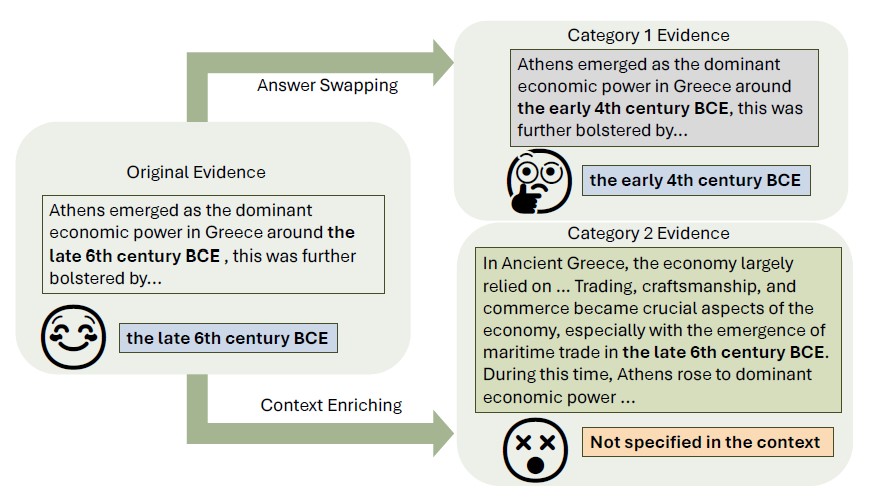
ReEval: Automatic Hallucination Evaluation for Retrieval-Augmented Large Language Models via Transferable Adversarial Attacks
Figure 1: An example of how original evidence is edited by ReEval. The question is “When did Athens emerge as the wealthiest Greek city state?” The desirable answers, respectively, for answer swapping (Category 1) and context enriching (Category 2) are “the early 4th century BCE” and “the late 6th century BCE”. ChatGPT answers are next to the emoji.
Despite remarkable advancements in mitigating hallucinations in large language models (LLMs) by retrieval augmentation, it remains challenging to measure the reliability of LLMs using static question-answering (QA) data. Inspired by adversarial machine learning, we investigate the feasibility of automatically perturbing existing static benchmarks for dynamic evaluation. Specifically, this paper presents ReEval, an LLM-based framework using prompt chaining to perturb the original evidence and generate new test cases for evaluating the LLMs’ reliability in using new evidence for answering.
Dr. Wenpeng Yin joined the Cognitive Computation Group as a postdoctoral researcher in 2017.
Dr. Wenpeng Yin
He is currently a tenure-track Assistant Professor at Penn State University, heading the AI4Research lab. In between, he served as Assistant Professor at Temple University (2022) and a Senior Research Scientist at Salesforce (2019-2021). He got his Ph.D. degree from the University of Munich, Germany, in 2017.
Wenpeng’s research interests span AI for Research, Human-Centered AI, Large Language Models & NLP & Computer Vision, and general machine learning algorithms. He has been the Senior Area Chair for NAACL’2021, ACL Rolling Review, IJCNLP-AACL’23, LREC-COLING’24, and EACL’24.
Hi, Wenpeng! Great to hear from you. Please tell me where you’re living and what you’re doing these days.
I live in Berwyn, conveniently close to King of Prussia (KOP), PA, maintaining a balanced lifestyle that seamlessly blends my dedication to research with the joy of cleaning my yard, preparing it to embrace the warm spring.
Nice! What kinds of plants grow in your yard?
I want to grow watermelons (we harvested three big watermelons with yellow flesh last summer), tomatoes, and cucumbers in the backyard, and some tulips in the front yard…but I just found deer have eaten all the new leaves of the tulips.
Aw, I’m sorry to hear about the tulips. Hope they recover, and wishing you all the best with your garden!
What are the most rewarding things about your current work?
Two dimensions: i) as a supervisor, I take immense pride in witnessing the remarkable growth of PhD students who initiate their journey in NLP research, eventually evolving into independent contributors to research projects and champions in disseminating our findings; ii) recognizing the impact of our work on the industry, evidenced by their outreach for commercial applications or collaborative endeavors, underscores our tangible contribution to both the industry and society at large.
The most surprising?
NLP research at Penn State only started in 2016 when Prof. Rebecca Jane Passonneau joined, and Penn State does not even have an undergraduate-level NLP course, which is exactly the one I have recently proposed.
I wish you all the best with putting that course together! How connected is your work now with the work you did in our group?
I’ve been extending my recent work, building upon my projects in CCG. Initially, my focus in CCG was on textual entailment, which played a pivotal role as indirect supervision for various NLP tasks. One prominent thread in my recent research (Arxiv 2024, CoNLL’22, TACL’22, ACL’23 Tutorial) represents a natural extension of this earlier work. Additionally, my involvement in the LORELEI project in CCG, which centered around low-resource language translation, further enriched my research portfolios, such as our research work about machine translation evaluation (ICLR’24), and one of my main research directions, “Human-Centered AI”.
What new development(s) in the field of NLP are you excited about right now?
Yeah, NLP has come a long way, especially with these large language models (LLMs) making waves. But what really gets me pumped are these four things: i) “NLP for Other Disciplines“: Some folks thought NLP research was done for when these LLMs came into the scene, rocking super high performance on tasks we’ve been wrestling with for ages. Surprise, surprise—turns out, now everyone thinks NLP is the bee’s knees. It’s like this golden era where all sorts of disciplines are jumping on the NLP train, not just regular folks but also researchers from other fields who are using it to automate their research game. NLP’s never been in the spotlight like this before. ii) “NLP with Cross-Modalities“: NLP has become more effortlessly integrated with various modalities. It signifies that we’ve discovered a way to seamlessly blend knowledge across different modes, allowing information to flow smoothly between them. This was something hard to fathom just a couple of years ago. iii) “LLM+Agents“: LLM+agent combos are shaping up to be the next big thing. Even though universal LLMs are hogging the limelight, it turns out we still need specialized systems for specific domains. iv) “Open Source“: Open source is the rockstar in NLP research, making things zoom ahead and keeping everything out in the open. It’s like the norm now, making research faster and more transparent.
Thoughts about the state of AI?
Let me first look at the positive side of things: i) The behavior of AI systems today is nothing short of mind-blowing compared to just a couple of years ago. We’re witnessing an influx of potential applications that were once beyond imagination, opening up exciting possibilities. Now, let’s explore the downsides: i) Inequality is widening across the globe. Different fields benefit from AI unevenly, and people in various geographical areas have unequal access to the latest AI products and infrastructures. The dominance of top AI products by a handful of companies and a select few countries contributes to this disparity. ii) Security concerns are intensifying, with issues like forged images and videos becoming more prevalent. While AI systems often showcase unprecedented performance, it’s crucial to acknowledge that researchers still grapple with understanding the inner workings of these systems. The interpretability and control of AI systems remain challenging, leaving room for potential misuse. iii) In academia, there’s a heavy focus on studying Large Language Models (LLMs), and constructing benchmarks to evaluate their performance. Unfortunately, much of this research is heavily influenced by data-intensive and computation-intensive LLMs. This dominance limits the resources available to researchers for delving into the true nature of intelligence.
How are things outside of work?
We’re managing quite well. Our days are primarily occupied with shuttling the kids to a variety of clubs—soccer, dance, piano, gymnastics, and more. Surprisingly, weekends prove to be even busier than weekdays. Fortunately, our proximity to Philadelphia adds a delightful dimension to our lives, offering a diverse array of places like parks, museums, and various activities to explore regularly.
Excellent! I was glad to hear when you returned to the area, and it’s nice knowing that you’re still nearby. Do you have a memory to share from your time with the group?
Honestly, one memory that sticks with me from my time at CCG is when my daughter was diagnosed with a brain tumor just five months after joining. It meant spending practically every day at CHOP for about six months. It was a tough period, but what made it bearable was the incredible support from my CCG colleagues. I’m really grateful for their kindness and understanding, especially Dan, who was so flexible with my work during that challenging time. Those experiences, along with the group activities Dan organized, have had a big impact on how I now manage my own group at PSU.
I remember that time well. I’m glad you felt so supported, and that you’re passing that on!
Please tell me about something you’ve read recently that you would recommend.
My wife and I recently embarked on a shared literary adventure, immersing ourselves in the book ‘A Woman Makes a Plan: Advice for a Lifetime of Adventure, Beauty, and Success‘ by Maye Musk. While the computer community recognizes Elon Musk for his groundbreaking ventures like OpenAI, Tesla, PayPal, and SpaceX, we were intrigued by the legendary status of his mother, Maye Musk. Her story fascinated us, and we eagerly sought wisdom from her book, uncovering the depth of her legendary status as a woman, and the realm of parenting and educating children. Maye Musk’s experiences and insights transcend borders, proving that legends can be forged regardless of one’s country of origin, gender, or age.
Any advice for the current students and postdocs in the group?
It’s a bit tricky to say whether the current students and postdocs are in the best era (thanks to cool stuff like LLMs) or the toughest one (e.g., publishing papers is getting trickier). But the big lesson from Dan that sticks with me is this: think about what kind of AI/NLP system you want to create, instead of just following the research of others. By figuring out your own research tastes and goals and sticking to them, you’re on the best path to stand out in this community.
That’s great. Thank you so much for this interview! For more information on Dr. Wenpeng Yin, please visit his website.
In today’s rapidly evolving field of Natural Language Processing (NLP), the quest for achieving deeper semantic understanding of texts continues to accelerate. In this new paper, “Event Semantic Classification in Context,” we demonstrate how classifying events from multiple perspectives can greatly enhance machines’ ability to understand and reason about events.
Understanding the Complex Realm of Event Semantics
Instead of the broad-brush approach of classifying easily understandable lexical items such as nouns, we delve into the nuanced domain of events. Events in texts are not mere occurrences; they are the pivot around which a narrative’s temporal dynamic, causality, and thematic progression revolve. This research classifies events based on six properties: modality, affirmation, specificity, telicity, durativity, and kinesis.
The Six Essential Properties for Event Classification:
Modality (Actuality) – Determines whether an event actually takes place.
Affirmation – Indicates whether an event is described affirmatively or negatively.
Specificity (Genericity) – Ascertains whether an event is a singular occurrence or part of a general trend.
Telicity (Lexical Aspect) – Identifies whether an event has a definite end.
Durativity (Punctuality) – Determines the duration over which an event unfolds.
Kinesis – Differentiates between states and actions.
The significance of these classifications extends beyond mere semantic labeling. They provide foundational insights into how events are grounded in time and reality, laying the groundwork for more refined event understanding and reasoning—a leap forward in machine comprehension of narratives.
The ESC Dataset
One of the main contributions of this work is the introduction of the ESC (Event Semantic Classification) dataset. This novel bilingual dataset, encompassing both English and Chinese, is specifically crafted for fine-grained semantic classification tasks. It stands out for its inclusion of all example sentences from WordNet featuring frequent verbs, tagged with six aforementioned semantic properties concerning events.
Still Challenging for ChatGPT
We find that these fine-grained semantic understanding tasks are challenging for ChatGPT, while they can be well solved by fine-tuning smaller language models like XLM-RoBERTa.
Advancing Event Understanding and Reasoning
By integrating the classification of events according to these detailed semantic properties, the research demonstrates a marked improvement in event understanding and reasoning capabilities. This is meticulously evidenced through experiments focusing on tasks such as event extraction, temporal relation extraction, and subevent relation extraction. Notably, the dataset and the sophisticated classification models designed in this study are instrumental in making substantive advancements in these areas. By leveraging innovative datasets like ESC and pushing the boundaries of event classification, the NLP field is inching closer to unlocking the full potential of machines in understanding the intricacies of human language and thought.
To read the full paper: Haoyu Wang, Hongming Zhang, Kaiqiang Song, Dong Yu, and Dan Roth, Event Semantic Classification in Context, Findings of EACL (2024). Dataset forthcoming.
Haoyu Wang is a third-year PhD student in the Cognitive Computation Group at the University of Pennsylvania, with a research interest in event-centric natural language understanding.