The Forty-Second International Conference on Machine Learning (ICML) starts off today in Vancouver, Canada. We’re excited to share the works that will be presented by the group and our collaborating authors. You can find links to our ICML 2025 papers below!
ReFocus: Visual Editing as a Chain of Thought for Structured Image Understanding
This work presents ReFocus, a framework that equips multimodal LLMs with the ability to generate “visual thoughts” by performing visual editing on the input image through code, shifting and refining their visual focuses. With experiments on a wide range of structured image understanding tasks involving tables and charts, we present an in-depth analysis of the effects of different visual edits and the ways ReFocus can edit the input image until an answer is reached.
Tuesday, July 15, 4:30 pm PDT — Poster Session 2 West
GIVE: Structured Reasoning of Large Language Models with Knowledge Graph Inspired Veracity Extrapolation
This paper introduces GIVE (Graph Inspired Veracity Extrapolation), a framework that enhances Large Language Models’ reasoning on knowledge-intensive tasks by combining their internal knowledge with minimal, structured external knowledge graph cues. The method enables smaller LLMs to achieve or exceed the performance of larger models on complex scientific reasoning tasks, while also reducing hallucination.
The 2025 International Conference on Learning Representations (ICLR) is happening this week in Singapore. We’re excited to share the work that will be presented and published by the group and our collaborating authors. You can find links to our ICLR 2025 papers below!
BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models
Language models often struggle with reliable and consistent decisions under uncertainty, partially because they can’t reliably estimate the probability of each choice. We propose BIRD, a framework that significantly enhances LLM decision making under uncertainty. BIRD leverages LLMs for world modeling and constructs a Bayesian network using LLM-generated variables, enabling interpretable and trustworthy probability estimates.
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). For reliable assessment, each standard instance in MuirBench is paired with an unanswerable variant that has minimal semantic differences.
Fei Wang, Xingyu Fu, James Y. Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao Chen, MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding ICLR (2025)
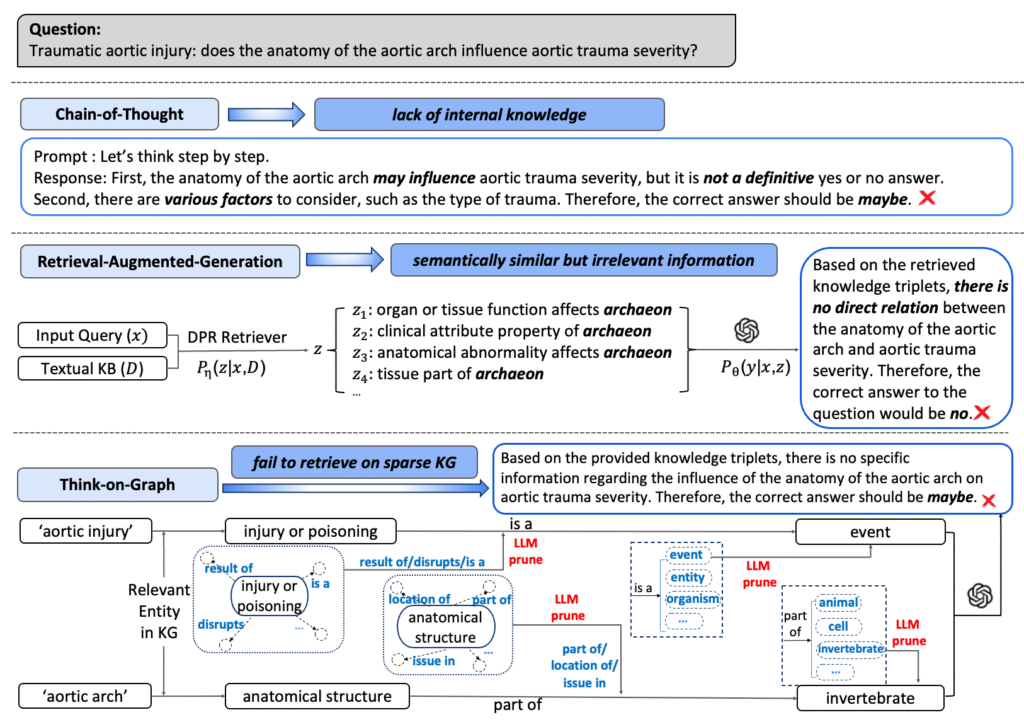
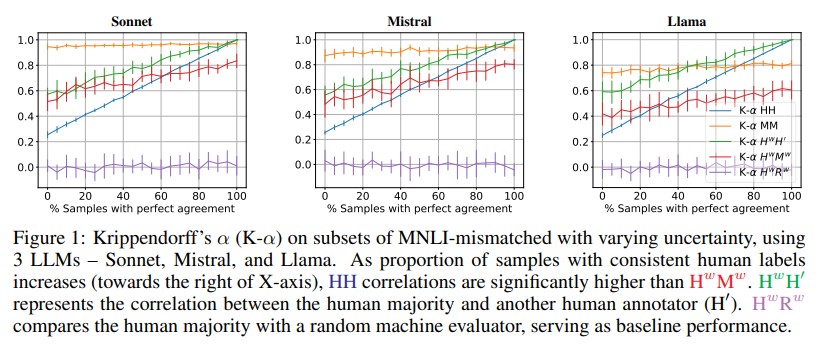
Beyond correlation: The Impact of Human Uncertainty in Measuring the Effectiveness of Automatic Evaluation and LLM-as-a-Judge
The effectiveness of automatic evaluation of generative models is typically measured by comparing labels generated via automation with labels by humans using correlation metrics. In this paper, we show how *relying on a single aggregate correlation score* can obscure fundamental differences between human labels and those from automatic evaluation, including LLM-as-a-Judge. Based on these findings, we propose stratifying data by human label uncertainty to provide a more robust analysis and introduce a new metric to better measure the effectiveness of automatic evaluations.
Updated with presentation times and dates (note: not chronological, even though the first one is on April 30; so is the last). ___ * Here’s a blog post from the NAACL organizing committee about their name change.
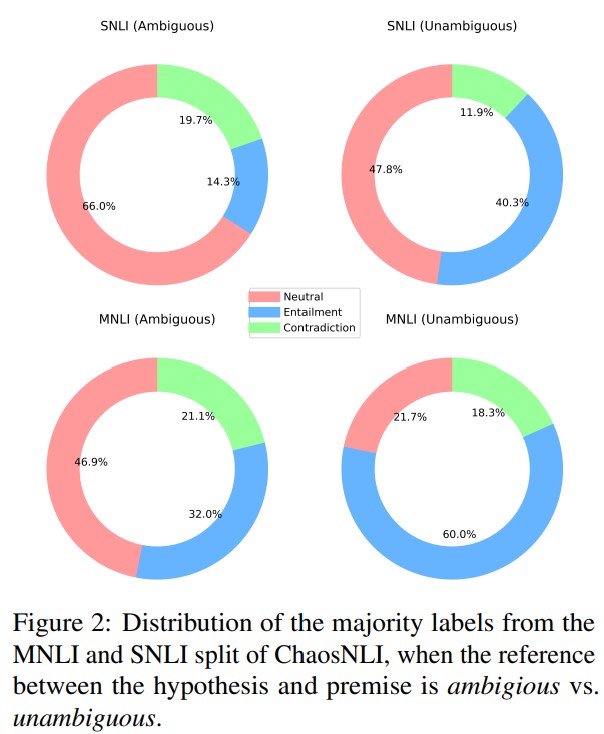
On Reference (In-)Determinacy in Natural Language Inference
This paper introduces RefNLI, a diagnostic benchmark for identifying reference ambiguity in Natural Language Inference examples. We provide insight into how the reference determinacy assumption (the assumption that premise and hypothesis refer to the same context) impacts the downstream utility of NLI models, and discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI.
Wednesday, April 30, Session C: Oral/Poster 2, Hall 3, 14:00-15:30.
Towards Long Context Hallucination Detection
This paper studies hallucination detection where the context length is long (>=512 tokens). We construct a dataset to evaluate the task and propose a method to approach it.
Siyi Liu, Kishaloy Halder, Zheng Qi, Wei Xiao, Nikolaos Pappas, Phu Mon Htut, Neha Anna John, Yassine Benajiba, and Dan Roth, Towards Long Context Hallucination Detection. NAACL Findings (2025)
Friday, May 2, Session J: Oral/Poster 7, Hall 3, 9:00-10:30.
Open Domain Question Answering with Conflicting Contexts
We study open domain question answering when there is conflicting evidence presented on the web. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guides them through the process of reasoning with conflicting contexts.
Friday, May 2, Session J: Oral/Poster 7, Hall 3, 9:00-10:30.
H-STAR: LLM-driven Hybrid SQL-Text Adaptive Reasoning on Tables
Existing approaches to tabular reasoning employ either textual reasoning, which excels in semantic interpretation but struggles with mathematical operations, or symbolic reasoning, which handles computations well but lacks semantic understanding. H-STAR, a novel method introduced in this paper, integrates text comprehension with SQL-like logic to effectively answer queries from structured tables.
Thursday, May 1, Session H: Oral/Poster 5, Hall 3, 14:00-15:30.
TRANSIENTTABLES: Evaluating LLMs’ Reasoning on Temporally Evolving Semi-structured Tables
The ability to reason over time allows us to identify future steps and to understand the effects of decisions on our lives. However, large language models are typically trained on static datasets, limiting their ability to perform effective temporal reasoning. To assess the temporal reasoning capabilities of LLMs, this paper presents the TRANSIENTTABLES dataset, with questions derived from over 14,000 tables, spanning multiple time periods.
Friday, May 2, Session K: Oral/Poster 8, 11:00-12:30 (presentation 11:45).
Enhancing Temporal Understanding in LLMs for Semi-structured Tables
We introduce the C.L.E.A.R. prompting framework and auxiliary cross-format training to enhance LLM performance in temporal tabular reasoning. Our findings demonstrate that our method improves evidence-based reasoning across various models. Additionally, our experimental results reveal that indirect supervision with auxiliary unstructured data (TRAM) substantially boosts model performance.
Thursday, May 1, Session H: Oral/Poster 5, Hall 3, 14:00-15:30.
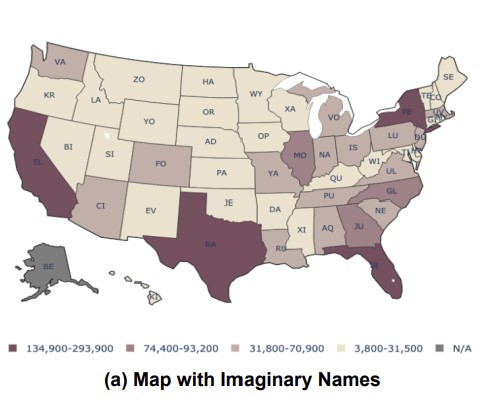
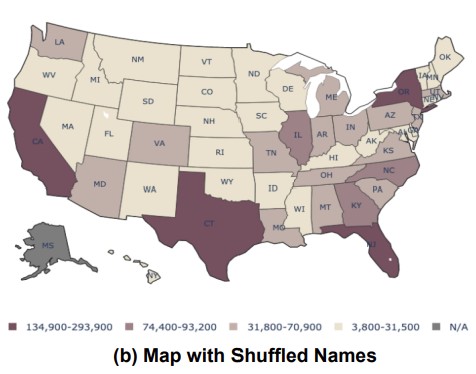
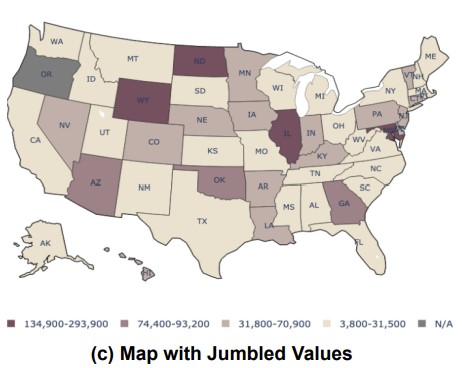
MAPWise: Vision-Language Models for Advanced Map Queries
Revised maps with counterfactual data, forcing the models to rely on the maps themselves.
This paper introduces a new benchmark for evaluating vision-language models (VLMs) on choropleth map question answering, featuring diverse maps and question types across multiple geographic regions. Evaluation of several VLMs reveals significant performance gaps, highlighting the need for further research in this area and providing a resource for future model development.
NTSEBENCH: Cognitive Reasoning Benchmark for Vision Language Models
NTSEBENCH is a Vision-Language Model benchmark dataset with 2,728 questions and 4,642 images from India’s NTSE exam, to evaluate VLMs on cognitive multimodal reasoning.
Friday, May 2, Session K: Oral/Poster 8, Hall 3, 11:00-12:30.
Aligning to Constraints for Data-Efficient Language Model Customization
This paper proposes ACT (Aligning to ConsTraints), a unified and efficient Language Model customization framework using automatic constraint verifiers to provide supervision signals for adapting models to downstream tasks.
Tuesday, May 6, Gather Session 2, online, 15:00-16:30.
Leveraging LLM For Synchronizing Information Across Multilingual Tables
We explored the application of large language models (LLMs) for multilingual information synchronization, focusing on improving the accuracy and coherence of updates to Wikipedia tables in low-resource languages.
The 2024 Annual Meeting of the Association for Computational Linguistics (ACL) is underway in Bangkok! We’re excited to share the work that’s being presented and published from CCG and our collaborating authors. You can find links to our ACL papers below!
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models
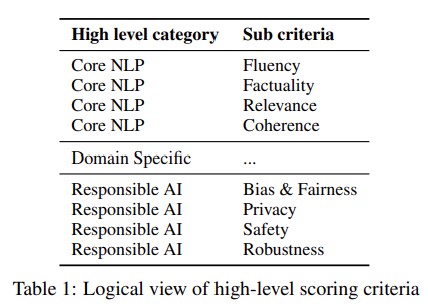
In this position paper, we argue that human evaluation of generative large language models (LLMs) should be a multidisciplinary undertaking that draws upon insights from disciplines such as user experience research and human behavioral psychology to ensure that the experimental design and results are reliable. To design an effective human evaluation system in the age of generative NLP, we propose the ConSiDERS-The-Human evaluation framework, consisting of 6 pillars — Consistency, Scoring Criteria, Differentiating, User Experience, Responsible, and Scalability.
Winner of the Outstanding Paper Award at the ACL2024 Workshop on Knowledgeable LMs Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval
Retrieving relevant tables containing the necessary information to accurately answer a given question over tables is critical to open-domain question-answering (QA) systems. However, many questions require retrieving multiple tables and joining them through a join plan that cannot be discerned from the user query itself. In this paper, we introduce a method that uncovers useful join relations for any query and database during table retrieval. We use a novel re-ranking method formulated as a mixed-integer program that considers not only table-query relevance but also table-table relevance that requires inferring join relationships.
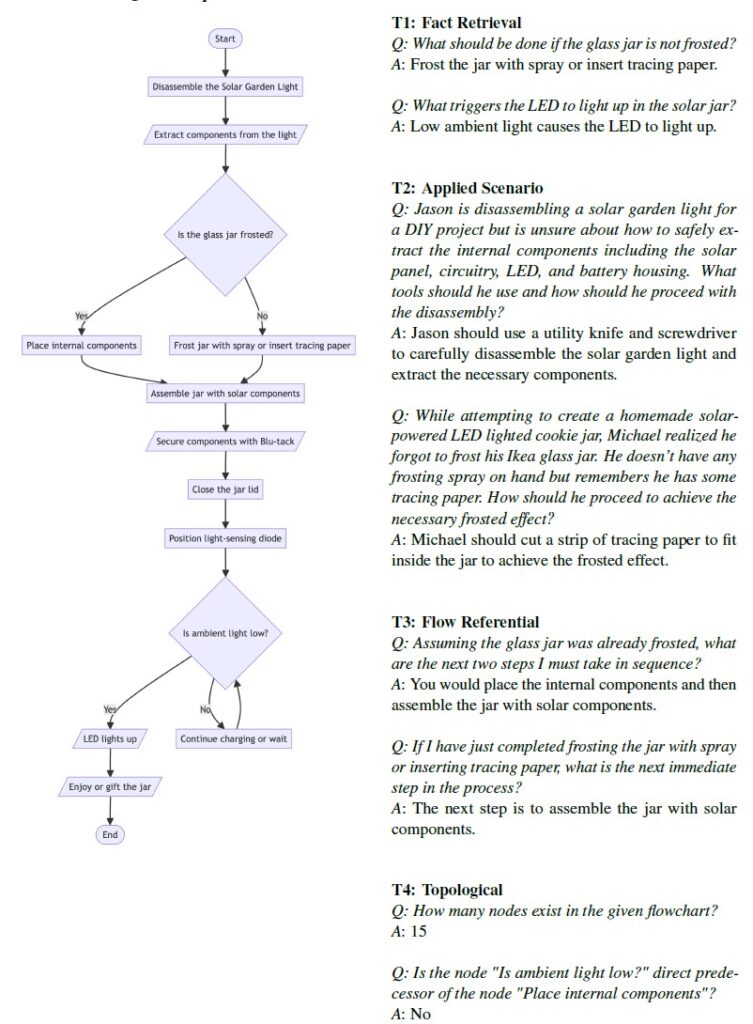
FlowVQA: Mapping Multimodal Logic in Visual Question Answering with Flowcharts
This paper introduces FlowVQA to overcome the shortcomings of existing visual question answering benchmarks in visual grounding and spatial reasoning. FlowVQA features 2,272 flowchart images and 22,413 question-answer pairs to evaluate tasks like information localization, decision-making, and logical reasoning. The evaluation of various multimodal models highlights FlowVQA’s potential to advance multimodal modelling and improve visual and logical reasoning skills.
Evaluating LLMs’ Mathematical Reasoning in Financial Document Question Answering
In this paper, we assess LLM robustness in complex mathematical reasoning with financial tabular datasets, revealing that LLMs struggle with increasing table and question complexity, especially with multiple arithmetic steps and hierarchical tables. The new EEDP technique enhances LLM accuracy and robustness by improving domain knowledge, extracting relevant information, decomposing complex questions, and performing separate calculations.
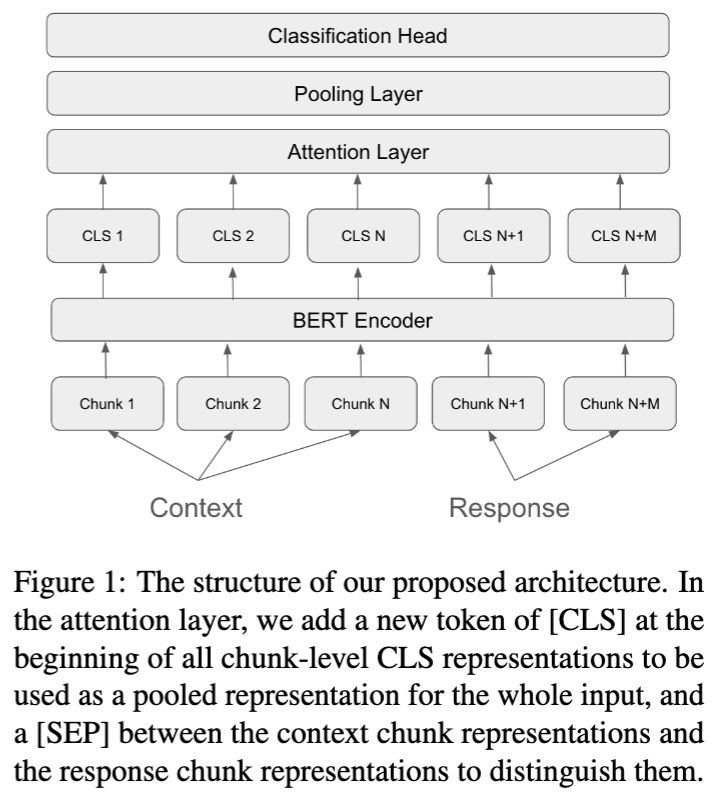
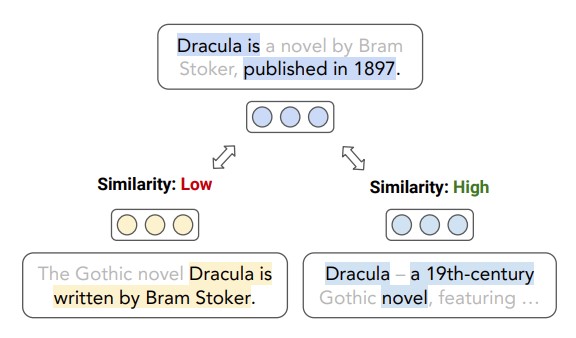
Sub-Sentence Encoder: Contrastive Learning of Propositional Semantic Representations
Figure 1: Given a proposition in a sentence (represented by a highlighted subset of tokens), the sub-sentence encoder produces a contextual embedding for the meaning of the proposition.
Text embeddings typically produce one embedding for the entire text sequence, but what if the text is long and says many things? Check out Sub-Sentence Encoder — A contextual text encoder model that learns to embed individual pieces of meaning in text.
What if you said that differently?: How Explanation Formats Affect Human Feedback Efficacy and User Perception
In this work, we study the effect of intermediate explanation formats on the effectiveness of human feedback for correcting QA model responses. Further, we investigate the properties of explanations which allow users to understand and trust responses.
ExpertQA: Expert-Curated Questions and Attributed Answers
This work conducts expert evaluation of responses to domain-specific questions according to various axes of attribution and factuality. Based on our evaluation, we present ExpertQA, a high-quality long-form QA dataset with 2177 questions spanning 32 fields, along with verified answers and attributions for claims in the answers.
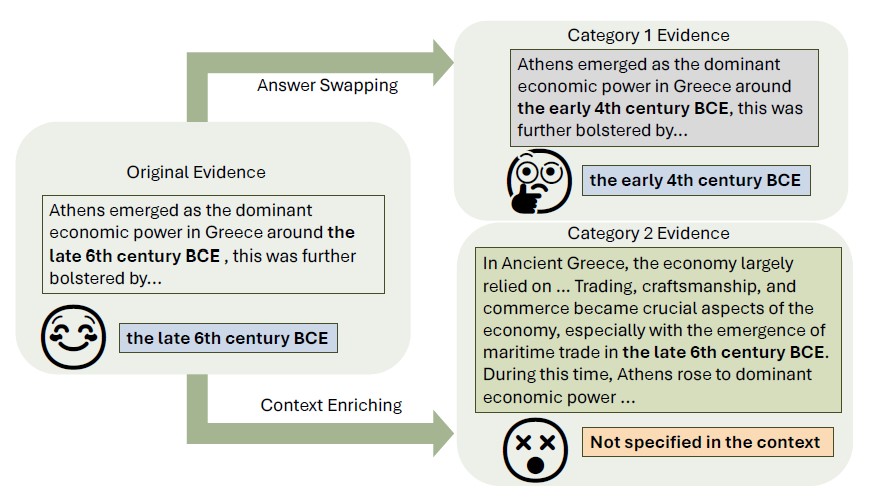
ReEval: Automatic Hallucination Evaluation for Retrieval-Augmented Large Language Models via Transferable Adversarial Attacks
Figure 1: An example of how original evidence is edited by ReEval. The question is “When did Athens emerge as the wealthiest Greek city state?” The desirable answers, respectively, for answer swapping (Category 1) and context enriching (Category 2) are “the early 4th century BCE” and “the late 6th century BCE”. ChatGPT answers are next to the emoji.
Despite remarkable advancements in mitigating hallucinations in large language models (LLMs) by retrieval augmentation, it remains challenging to measure the reliability of LLMs using static question-answering (QA) data. Inspired by adversarial machine learning, we investigate the feasibility of automatically perturbing existing static benchmarks for dynamic evaluation. Specifically, this paper presents ReEval, an LLM-based framework using prompt chaining to perturb the original evidence and generate new test cases for evaluating the LLMs’ reliability in using new evidence for answering.
In today’s rapidly evolving field of Natural Language Processing (NLP), the quest for achieving deeper semantic understanding of texts continues to accelerate. In this new paper, “Event Semantic Classification in Context,” we demonstrate how classifying events from multiple perspectives can greatly enhance machines’ ability to understand and reason about events.
Understanding the Complex Realm of Event Semantics
Instead of the broad-brush approach of classifying easily understandable lexical items such as nouns, we delve into the nuanced domain of events. Events in texts are not mere occurrences; they are the pivot around which a narrative’s temporal dynamic, causality, and thematic progression revolve. This research classifies events based on six properties: modality, affirmation, specificity, telicity, durativity, and kinesis.
The Six Essential Properties for Event Classification:
Modality (Actuality) – Determines whether an event actually takes place.
Affirmation – Indicates whether an event is described affirmatively or negatively.
Specificity (Genericity) – Ascertains whether an event is a singular occurrence or part of a general trend.
Telicity (Lexical Aspect) – Identifies whether an event has a definite end.
Durativity (Punctuality) – Determines the duration over which an event unfolds.
Kinesis – Differentiates between states and actions.
The significance of these classifications extends beyond mere semantic labeling. They provide foundational insights into how events are grounded in time and reality, laying the groundwork for more refined event understanding and reasoning—a leap forward in machine comprehension of narratives.
The ESC Dataset
One of the main contributions of this work is the introduction of the ESC (Event Semantic Classification) dataset. This novel bilingual dataset, encompassing both English and Chinese, is specifically crafted for fine-grained semantic classification tasks. It stands out for its inclusion of all example sentences from WordNet featuring frequent verbs, tagged with six aforementioned semantic properties concerning events.
Still Challenging for ChatGPT
We find that these fine-grained semantic understanding tasks are challenging for ChatGPT, while they can be well solved by fine-tuning smaller language models like XLM-RoBERTa.
Advancing Event Understanding and Reasoning
By integrating the classification of events according to these detailed semantic properties, the research demonstrates a marked improvement in event understanding and reasoning capabilities. This is meticulously evidenced through experiments focusing on tasks such as event extraction, temporal relation extraction, and subevent relation extraction. Notably, the dataset and the sophisticated classification models designed in this study are instrumental in making substantive advancements in these areas. By leveraging innovative datasets like ESC and pushing the boundaries of event classification, the NLP field is inching closer to unlocking the full potential of machines in understanding the intricacies of human language and thought.
To read the full paper: Haoyu Wang, Hongming Zhang, Kaiqiang Song, Dong Yu, and Dan Roth, Event Semantic Classification in Context, Findings of EACL (2024). Dataset forthcoming.
Haoyu Wang is a third-year PhD student in the Cognitive Computation Group at the University of Pennsylvania, with a research interest in event-centric natural language understanding.