The Conference on Empirical Methods in Natural Language Processing (EMNLP), celebrating its 30th anniversary, is underway in Suzhou, China, and the co-located 14th Joint Conference on Lexical and Computational Semantics (*SEM) kicks off tomorrow. We’re excited to share the works that will be presented by the group and our collaborating authors. You can find links to our EMNLP and *SEM 2025 papers below!
[Some summaries generated by AI.]
*SEM 2025 (11/08-11/09, co-located with EMNLP)
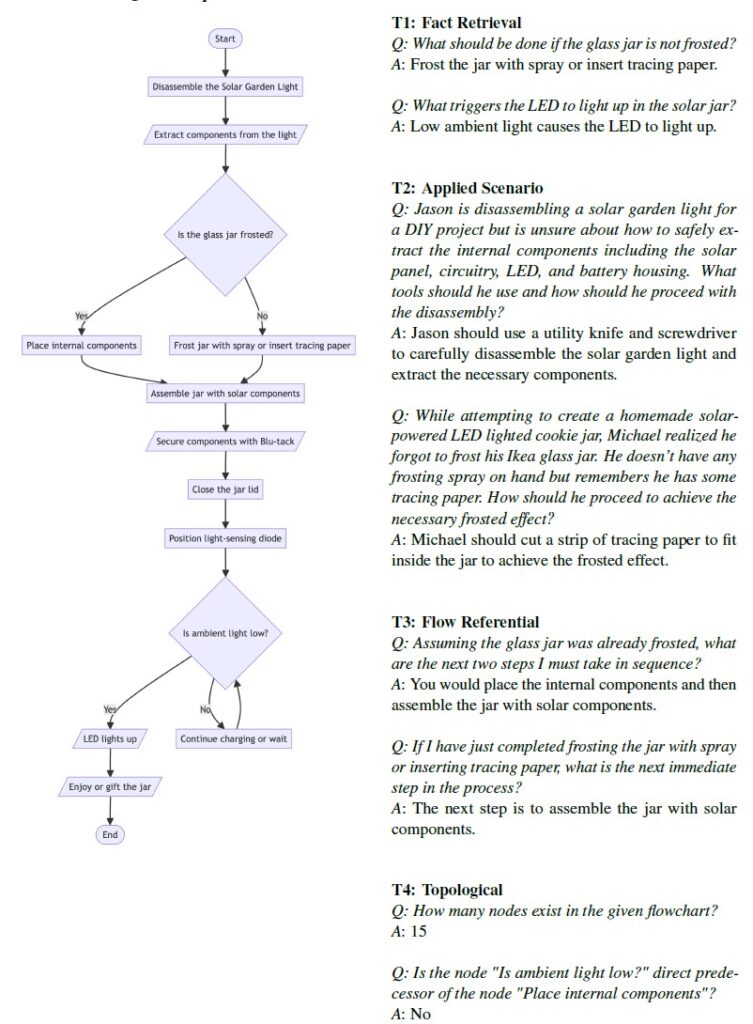
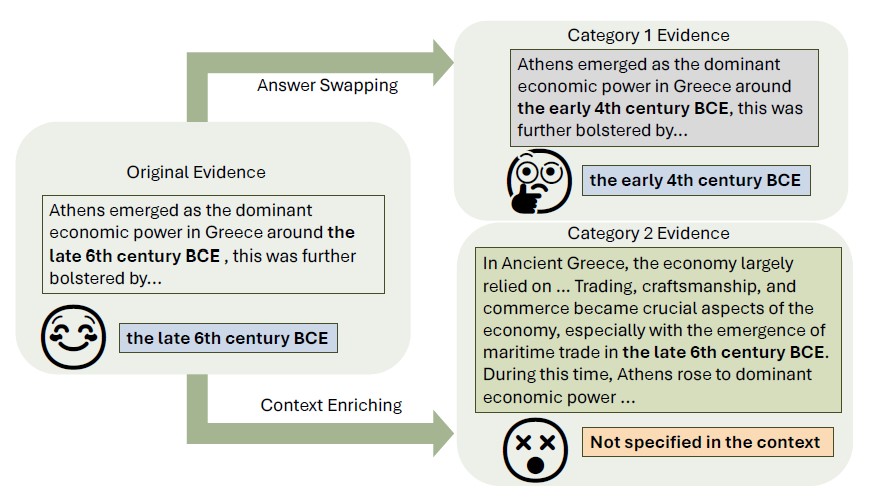
Cross-lingual Extractive Question Answering with Unanswerable Questions
This paper extends cross-lingual extractive QA, where models need to find answers in passages written in a language different from the question, to cases where no answer exists within the given context. Proposing two novel datasets and performing extensive experiments, we analyze the strengths and weaknesses of different language models and training strategies for this task as well as the effect of the language identity on the performance.
Yuval Gorodissky and Elior Sulem and Dan Roth, Cross-lingual Extractive Question Answering with Unanswerable Questions *SEM (2025)
Sunday, November 9, 09:00-10:30 local time — Virtual Poster Session 5
EMNLP 2025 (11/5-11/9)
Conflicts in Texts: Data, Implication, Challenges
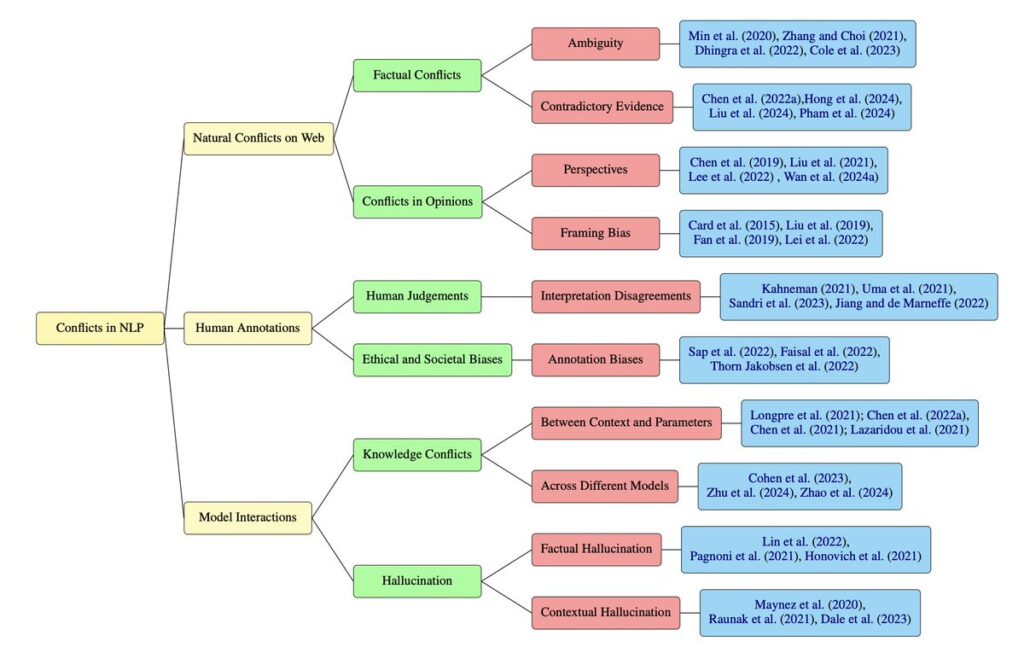
This survey examines how conflicting information arises in NLP—from inconsistencies in natural texts, to annotation disagreements, to model-level hallucinations and knowledge clashes—and unifies them under a common framework. We analyze their implications, highlight mitigation strategies, and chart future directions for building conflict-aware NLP systems that can better reconcile contradictions.
Siyi Liu and Dan Roth, Conflicts in Texts: Data, Implication, Challenges EMNLP-Findings (2025)
AutoCT: Automating Interpretable Clinical Trial Prediction with LLM Agents
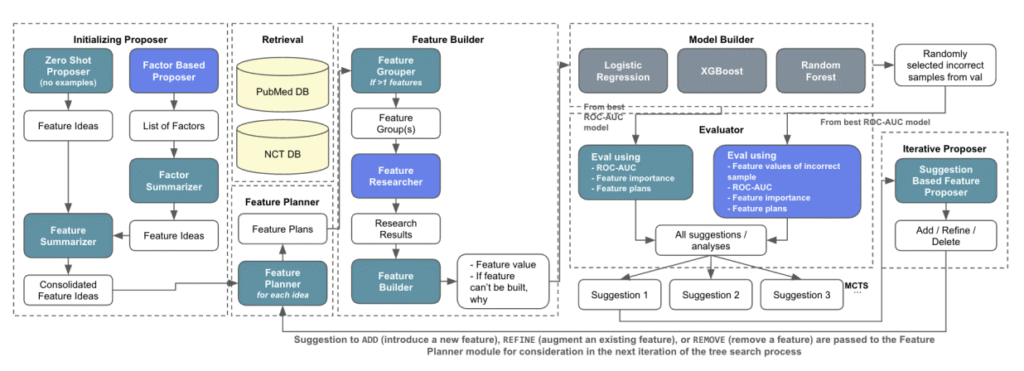
The paper introduces AutoCT, a framework that integrates large language models with classical machine learning to predict clinical trial outcomes. By autonomously proposing, constructing, and refining features through Monte Carlo Tree Search, AutoCT achieves competitive performance with state-of-the-art methods while maintaining interpretability and reducing reliance on human input.
Fengze Liu and Haoyu Wang and Joonhyuk Cho and Dan Roth and Andrew Lo, AutoCT: Automating Interpretable Clinical Trial Prediction with LLM Agents EMNLP (2025)
LogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval
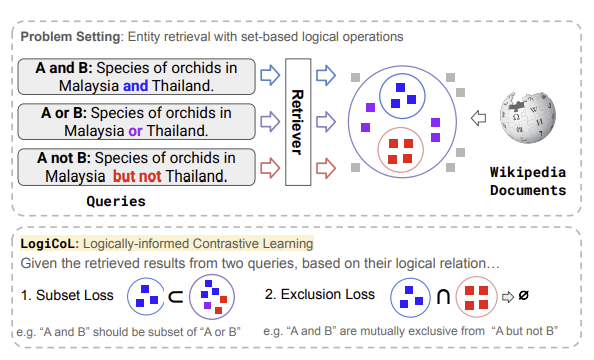
LogiCoL is a new training method for dense retrieval models that helps them better handle queries containing logical connectives (like “and,” “or,” “not”) by incorporating logical constraints directly into the learning process through contrastive learning. The authors demonstrate that this approach improves both retrieval accuracy and logical consistency when retrieving sets of Wikipedia entities that must satisfy complex logical relationships specified in queries.
Yanzhen Shen and Sihao Chen and Xueqiang Xu and Yunyi Zhang and Chaitanya Malaviya and Dan Roth, LogiCoL: Logically-Informed Contrastive Learning for Set-based Dense Retrieval EMNLP (2025)
Evaluating NL2SQL via SQL2NL
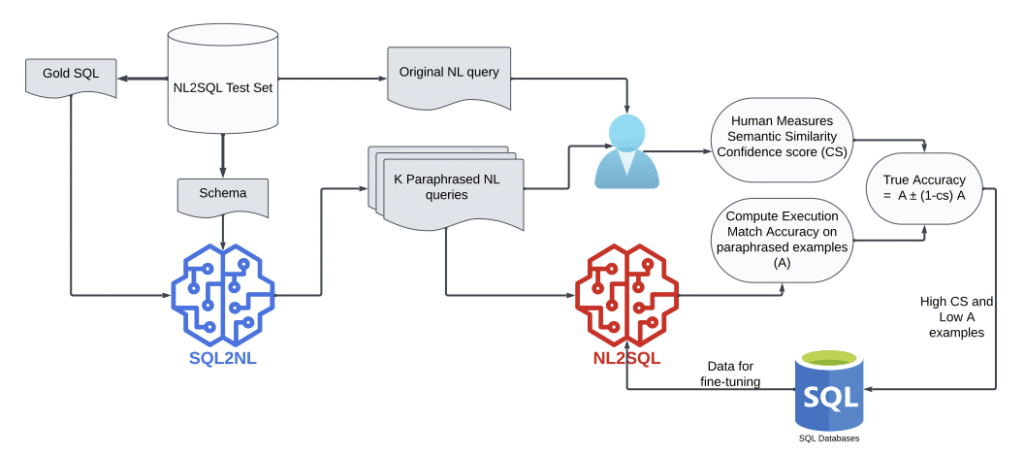
We propose a novel schema-aligned paraphrasing framework that leverages SQL-to-NL (SQL2NL) to automatically generate semantically equivalent, lexically diverse queries while maintaining alignment with the original schema and intent. This enables the first targeted evaluation of NL2SQL robustness to linguistic variation in isolation-distinct from prior work that primarily investigates ambiguity or schema perturbations.
Mohammadtaher Safarzadeh and Afshin Oroojlooyjadid and Dan Roth, Evaluating NL2SQL via SQL2NL EMNLP-Findings (2025)
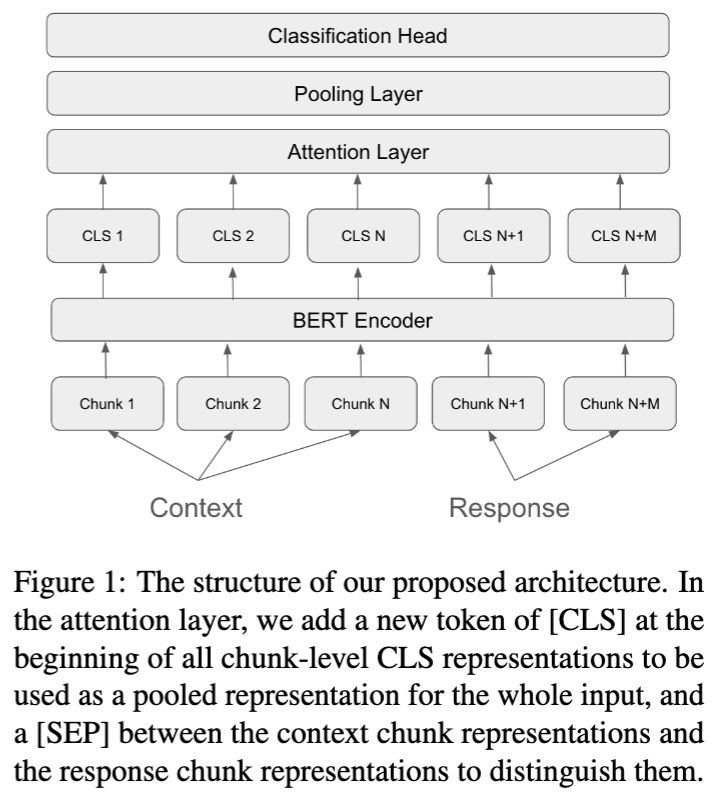
Weaver: Interweaving SQL and LLM for Table Reasoning
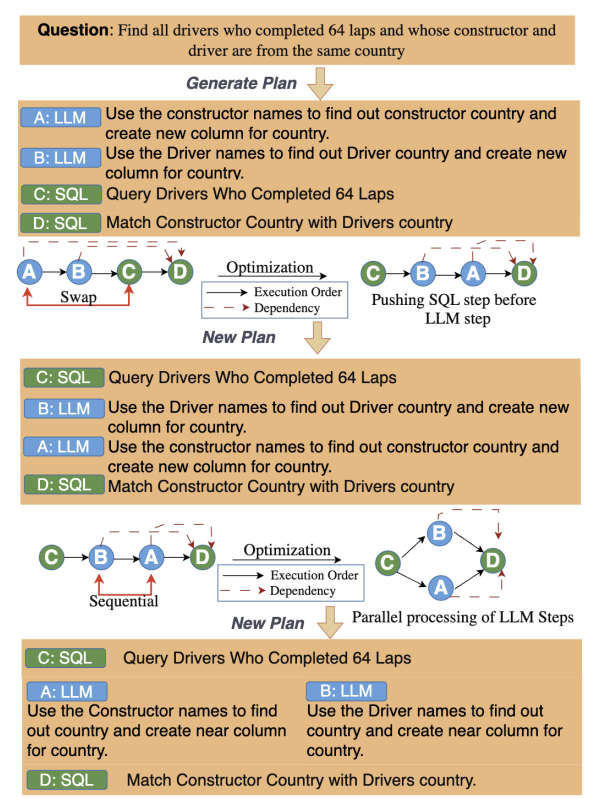
Weaver, a novel framework for question answering over tables where questions are complex and require reasoning, when you have unstructured columns, or need to combine logical operations with semantic understanding. Weaver dynamically combines SQL for retrieving and aggregating, together with the semantic reasoning capabilities of LLMs.
Rohit Khoja and Devanshu Gupta and Yanjie Fu and Dan Roth and Vivek Gupta, Weaver: Interweaving SQL and LLM for Table Reasoning EMNLP (2025)
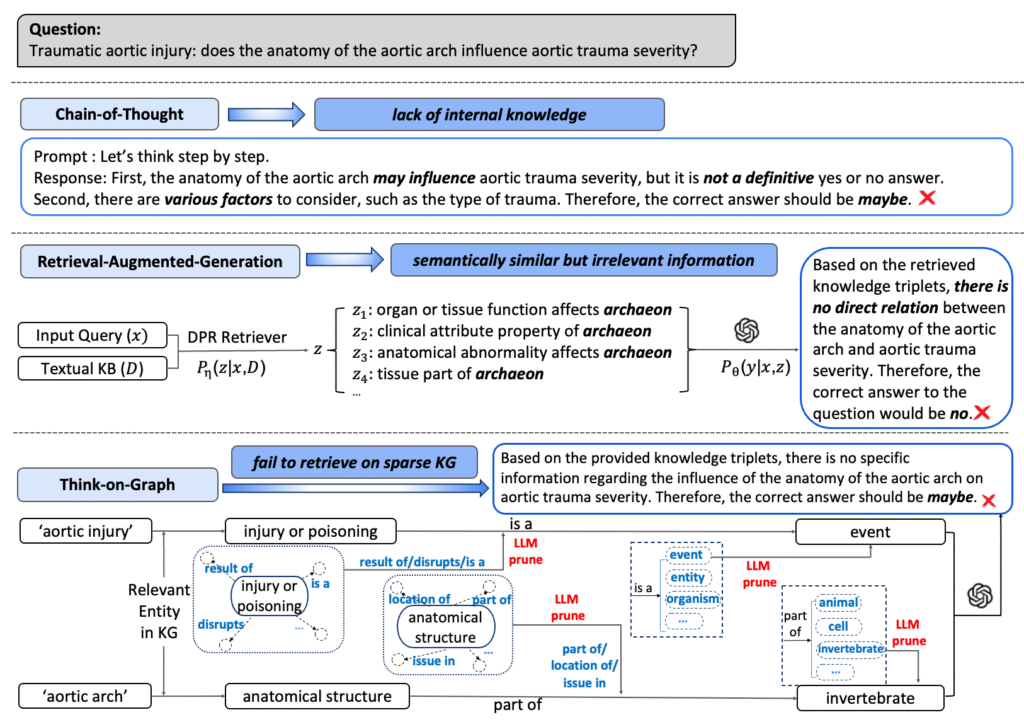
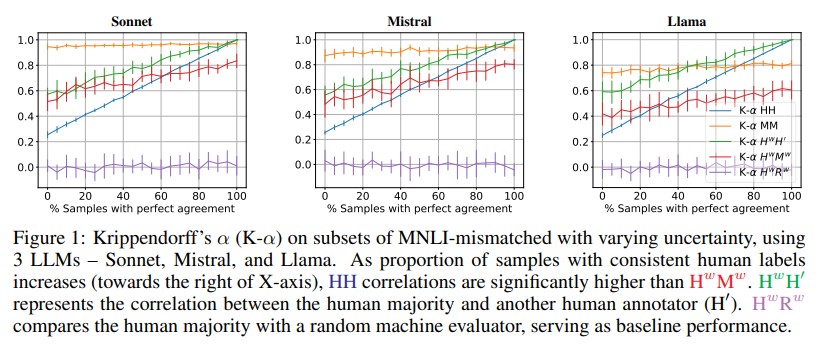
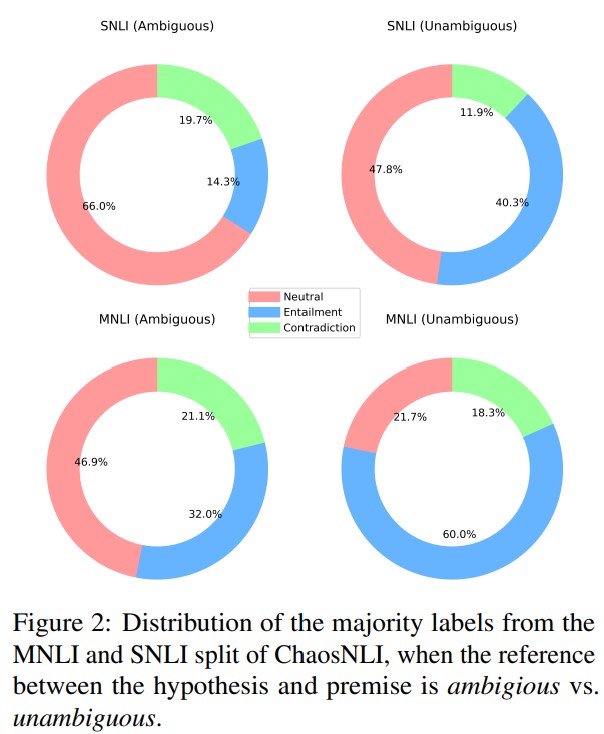
Rethinking LLM Uncertainty: A Multi-Agent Approach to Estimating Black-Box Model Uncertainty
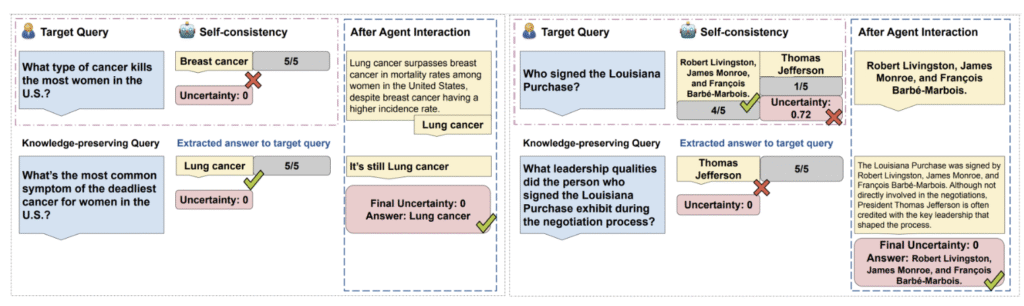
We show in this paper that LLMs are inconsistent on factual questions and can easily be biased by the additional context in the input, and we propose a multi-agent approach to improve answer consistency and uncertainty quantification.
Yu Feng and Phu Mon Htut and Zheng Qi and Wei Xiao and Manuel Mager and Nikolaos Pappas and Kishaloy Halder and Yang Li and Yassine Benajiba and Dan Roth, Rethinking LLM Uncertainty: A Multi-Agent Approach to Estimating Black-Box Model Uncertainty EMNLP-Findings (2025)