
The 2025 International Conference on Learning Representations (ICLR) is happening this week in Singapore. We’re excited to share the work that will be presented and published by the group and our collaborating authors. You can find links to our ICLR 2025 papers below!
BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models

Language models often struggle with reliable and consistent decisions under uncertainty, partially because they can’t reliably estimate the probability of each choice. We propose BIRD, a framework that significantly enhances LLM decision making under uncertainty. BIRD leverages LLMs for world modeling and constructs a Bayesian network using LLM-generated variables, enabling interpretable and trustworthy probability estimates.
Yu Feng, Ben Zhou, Weidong Lin, and Dan Roth, BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models ICLR (2025)
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding

We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). For reliable assessment, each standard instance in MuirBench is paired with an unanswerable variant that has minimal semantic differences.
Fei Wang, Xingyu Fu, James Y. Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao Chen, MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding ICLR (2025)
Beyond correlation: The Impact of Human Uncertainty in Measuring the Effectiveness of Automatic Evaluation and LLM-as-a-Judge
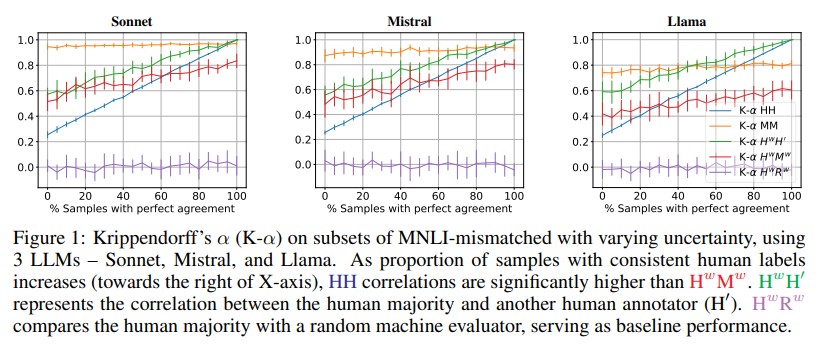
The effectiveness of automatic evaluation of generative models is typically measured by comparing labels generated via automation with labels by humans using correlation metrics. In this paper, we show how *relying on a single aggregate correlation score* can obscure fundamental differences between human labels and those from automatic evaluation, including LLM-as-a-Judge. Based on these findings, we propose stratifying data by human label uncertainty to provide a more robust analysis and introduce a new metric to better measure the effectiveness of automatic evaluations.
Aparna Elangovan, Lei Xu, Jongwoo Ko, Mahsa Elyasi, Ling Liu, Sravan Bodapati, and Dan Roth, Beyond correlation: The Impact of Human Uncertainty in Measuring the Effectiveness of Automatic Evaluation and LLM-as-a-Judge ICLR (2025)